Developer Documentation
# Let's Data : Focus on the data - we'll manage the infrastructure!
Cloud infrastructure that simplifies how you process, analyze and transform data.
The Problem
Here are some axiomatic truths about the relationship of data and the enterprise:
- Enterprises are creating data at an ever-faster pace: Clickstreams are logged, screen times are emitted, Ad interactions are recorded and even the performance statistics are logged. A single user session can potentially generate hundreds of megabytes of data per day.
- Data is fragmented: The data in the enterprise is fragmented. There is no "one-size-fits-all" data store. Today the data is stored in log files, databases, in-memory caches, messaging queues etc. Log files need to be processed to extract events and derive intelligence. ETL jobs on database are run frequently to get data in formats used by different systems. In-memory caches need to be populated, refreshed and reconciled with data sources. Data in messaging queues bridges the data from sources and consumers. Let's face it, this fragmented data needs to be processed, analyzed and transformed for different business needs
- Agility is a key business differentiator:Agility in being able to respond to different data transformation needs is a key business differentiator. Organizations that invest in data infrastructure to build production systems that can manage the data requirements are more successful than orgs that do not have dedicated infrastructure. Data agility is a key business differentiator in the enterprise.
- Data Infrastructures are costly:Building data infrastructures are costly. There is a cost to build, manage, maintain and evolve the data infrastructure constantly as the business needs change. The costs are complex, data engineers need to be hired, infrastructure needs to be acquired (or leased), code needs to be written and managed and operations need to be staffed.
- Data Infrastructures may not be the core business:Organizations whose core business is not data management find it increasingly difficult to build, maintain and even justify the costs related to data infrastructures. A retailer's core is inventory, selection, marketing and sales. Data augments these functions and being able to leverage a data infrastructure should not be prohibitive for such organizations
The data infrastructure needs to be robust, reliable and fault tolerant that is maintainable, operable and resilient. Each data processing, analysis and transformation requires custom compute code which isn't trivial – example, transient failures, rate limiting, batching, ordering and deduplication, checkpointing and failure restarts need to be handled for each destination. Logging, Metrics and Diagnostics need to be built in.
These tasks have nothing to do with the actual customer data / data transformation logic. Instead, they are the engineering grunt work required to build data compute infrastructure that can read reliably from the data source and write efficiently to the data destination.
This data compute infrastructure development happens again and again for different data sources and destinations, for different functional domains within the enterprise.
The Let's Data Value
#Let’s Data simplifies data pipelines and eliminates infrastructure pains. Our promise: "Focus on the data, we'll manage the infrastructure".
We've perfected our infrastructure code for AWS Services and built all the reliability, fault tolerance and diagnostics needed for a high-quality compute pipeline.
- Faster development times (42 dev weeks reduced to 8 dev weeks - Web Crawl Archive Case Study)
- Reduced costs (ROI calculations for a small sized data team suggests ~20% ($540K) savings in 1 year on AWS spend of ~ $40K per month, primarily from headcount reduction. Switching costs payback time is estimated at ~1.8 months
- Simplified development and reduced system complexity The #Let's Data Simplification Architecture Diagram
- Standardized development and operations (Full featured CLI, Console, logging, errors, metrics and task management builtin)
- High Performance & Elastic Scale (In a web crawler case study, #Let’s Data processed 219K files (~477 TB) from S3 using Lambda in 48 hours at a nominal cost of $ 5 per TB-Hour!)
- Zero cost version updates (AWS SDK upgrades, #Let's Data version upgrades etc.)
#Let's Data defines simple interfaces for developers to transform records - #Let's Data will read from AWS, write to AWS and takes care of the performance, errors, diagnostics and everything in-between.
#Let’s Data Minimum Viable Product (MVP) currently supports:- S3
- DynamoDB
- SQS
- Kinesis
- Lambda
- Kafka
- Sagemaker
- Momento Vector Index
- us-east-1 (N. Virginia)
- us-east-2 (Ohio)
- us-west-2 (Oregon)
- eu-west-1 (Ireland)
- ap-south-1 (Mumbai)
- ap-northeast-1 (Tokyo)
Here are some features at a glance:
- Connectors: #LetsData understands the different sources and destinations that data is read from and written to. We've built scalable infrastructure to read and write to these destinations reliably at scale. For example, AWS S3, SQS, DynamoDB and Kinesis etc. This simplifies the customer data processing since they do not need to invest resources to build these infrastructure components.
- Simple Programming Model: #LetsData defines a simple programming model inspired by the AWS Lambda event handlers - For example, customers implement a simple interfaces to tell us the start and end of records in an S3 file, we read the file and send them a completed record which they can transform and return to the framework to write to the destination
- Compute: #LetsData has built end-to-end automation around the popular processing frameworks such as AWS Lambda - this allows the customers to customize the processing framework according to their needs and scale at which they want to operate. For example, when processing log files from S3, running on network configuration with 100Gbps network to get maximum throughput etc.
- Diagnostics: #LetsData infrastructure builds in summarized and detailed logging, execution traces and adds metrics for each step in the pipeline. This allows the customers to monitor and measure the progress of their tasks and tune the workflow as needed.
- Errors & Checkpointing: Infrastructure components such as Error Reports, Redriving Error Tasks, Checkpointing etc are built into the framework - customers can rely on these to ensure high quality
- Costs Management: #LetsData allows high scale at efficient costs. We've built in cost optimization engines that monitor for cost reduction opportunities and de-scale/ reclaim resources to ensure efficient management of costs. Costs Management and Costs Transparency is also built into the website - customers can track and manage costs as needed.
Example: Clickstream data
Here is an example usecase to understand the # Let's Data value
An online retailer generates user engagement log files that contain click stream data. These files are stored in AWS S3. The business has a need to know items which the users disengage with the most. This means processing the raw log files and computing disengagement metrics for each product. The task is similar to map/reduce, but has the following challenges:
Challenges
- Managing map reduce reliably at scale is a challenge - one needs to handle things such as EC2 instances, EC2 networking, Map/Reduce software management, instance and software failures, adjusting scale/capacities for different scenarios. Instead of focusing on the log file format and map/reduce it, the team now spins its cycles on learning and coding the data infrastructure needed for successful execution of map reduce. Coding the successful execution of Map/Reduce is a defined problem that can be solved by using #LetsData - you dont need to manage the infrastructure! We'll manage the infrastructure, add/remove EC2 machines, configure lambda functions, retry errors, implement checkpointing and share the progress with detailed telemetry and error reports so that you know what failed and needs to be fixed.
- Handling the different error conditions is tricky - Files cannot be read, data is corrupt, destination has errors on publishing some records etc. When processing large data sets, errors such as these are a reality and systems need to account for each and every record that was errored. We automatically build in retries wherever possible, however when there is an error that is terminal, we generate error reports with links into the log file and record the offsets of the failing record. A dashboard lists all the files and each file's successful record and error record counts and link to the detailed error reports. In short, anything that one would need to build a high quality data pipeline is built into the #LetsData infrastructure
- Knowing what has been processed, where has it been processed, processing metrics such as latencies etc and what all is remaining is critical for the operations of the data processing work - we built that into the framework - each file's summarized and detailed execution trace is available and metrics broken down by network read, compute, network write and the overall latencies, similar performance metrics are generated to help understand and fix any performance issues that may exist.
Setup
To use #LetsData for the Process Log Files usecase, simply follow a few steps to setup the data pipeline - Tell us:
- where the log files are (s3Bucket)
- write a handler that processes the log file contents (similar to lambda handlers)
- the destination for the computed records (example: Amazon DynamoDB)
- the compute infrastructure that you like to use (example: EC2 machines, lambda, kubernetes etc.)
- the scale you'd like to use (EC2 instance types / lambda concurrency / kubernetes config etc.)
We'll read the files, call the handlers with the file contents, write the records to the destination, manage the infrastructure and scale as needed
Architecture
Reference architecture for processing files from S3. Interesting point to note is that the customer only needs to implement the parser and the reader (shaded in blue) - everything else is infrastructure managed by #Let's Data. (Re-iterating our promise - "Focus on the data, we'll manage the infrastructure")
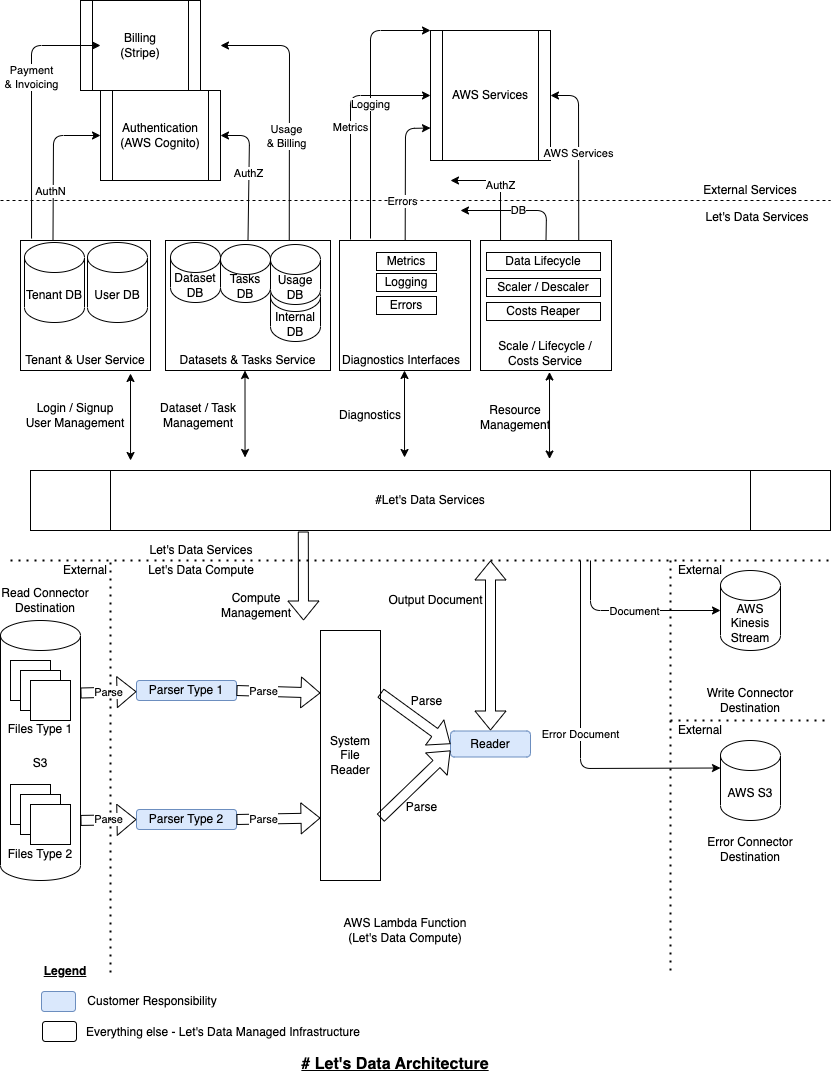
Quickstart
Here is the simple, high level setup that is needed to start processing files (called datasets) on #Let's Data: (or look at our detailed Step by Step Examples)
- Implement a #Let's Data parser interface (and the reader interface in some cases) for the S3 file. Here is the simplest file parsing usecase Single File Reader
Single File Reader Implementation
The Single File Reader usecase, as explained earlier, is when all the files are of a single type and the records in the file do not follow a state machine. Simple example is a log file where each line is a data record and the extracted document is transformed from each data record (line in the file).
In this simple example, you'll only need to implement the SingleFileParser interface. Here is a quick look at the interface methods, the implementation has detailed comments on what each method does and how to implement it:
- getS3FileType(): The logical name of the filetype. For example we could name the fileType as LOGFILE.
- getResolvedS3FileName():The filename resolved from the manifest name
- getRecordStartPattern():The start pattern / delimiter of the record
- getRecordEndPattern():The end pattern / delimiter of the record
- parseDocument():The logic to skip, error or return the parsed document
Here is an example implementation:
This example assumes that this code is built as LogFileParserImpl-1.0-SNAPSHOT.jar and uploaded to S3 at s3://logfileparserimpl-jar/LogFileParserImpl-1.0-SNAPSHOT.jar
- Define a manifest file to tell us which files need to be processed. Here is a simple Manifest File
Manifest File
- Since there is a single file type, the manifest lists only the log file names (not the FileType:FileName format that we use for multiple file reader)
- The S3 bucket may have many folders and files and we only need to process November's logfile data as part of the dataset. We add the relative path (Nov22/) from the bucket root to each individual file.
- This dataset contains 3 files that would be read. Each file would be a Datatask that would run independently and would log its progress separately.
This example assumes that this file is named manifest.txt and uploaded to S3 at s3://logfileparserimpl-manifest/manifest.txt
- Grant access to the read bucket, the parser interface jar and the manifest file. Here is a simple Access Grant
Access Grants
Find the User details: We need the following identifiers from the logged in user's data to enable access.
- #Let's Data IAM Account ARN: the logged in user's #Let's Data IAM Account ARN. This is the IAM user that was created automatically by #Let's Data when you signed up. All the dataset execution would be scoped to this user's security perimeter.
- UserId: the logged in user's User Id. We use the userId as the STS ExternalId to follow Amazon's security best practices. This would be an additional identifier (similar to MFA) that would limit someone inadvertently gaining access.
The console's User Management tab lists your IAM user ARN. You can also find it via CLI.
Create an IAM role and policy
- Define dataset configuration json file. Here is a simple Dataset Configuration
Dataset Configuration
For different languages, the dataset configuration differs in readConnector's artifactImplementationLanguage, artifactFileS3LinkResourceLocation / interfaceECRImageResourceLocation, artifactFileS3Link / interfaceECRImagePath and singleFileParserImplementationClassName attributes - Create a dataset. Here is a simple CLI command
Create a Dataset - CLI
The Resonance Labs, LLC
P.O. Box 3223
Redmond, WA 98073, USA